 TIKSL
TIKSL

This page is intended to start a discussion about I/O matters in the gigabit project. The main ideas are described, thought not all of them in greatest detail. If you feel we missed a part necessary for understanding, please let us know!
Please feel free to send any comments, ideas and suggestions to the authors (tradke@aei-potsdam.mpg.de, merzky@zib.de) or to the project mailing list (gigabit@aei-potsdam.mpg.de).
The TIKSL Project is part of the
"Gigabit Testbed
Süd+Berlin", and focuses on remote and distributed
visualization for numerical relativity applications, that is, for
Cactus. The main
goals for the project are:
In regard to the goals stated above, following points characterize the current state:
Remark: Recombination is (as I understood it) nothing else than reading some (chunked) data files, recreating the data structures, and writing them out into a single data file.
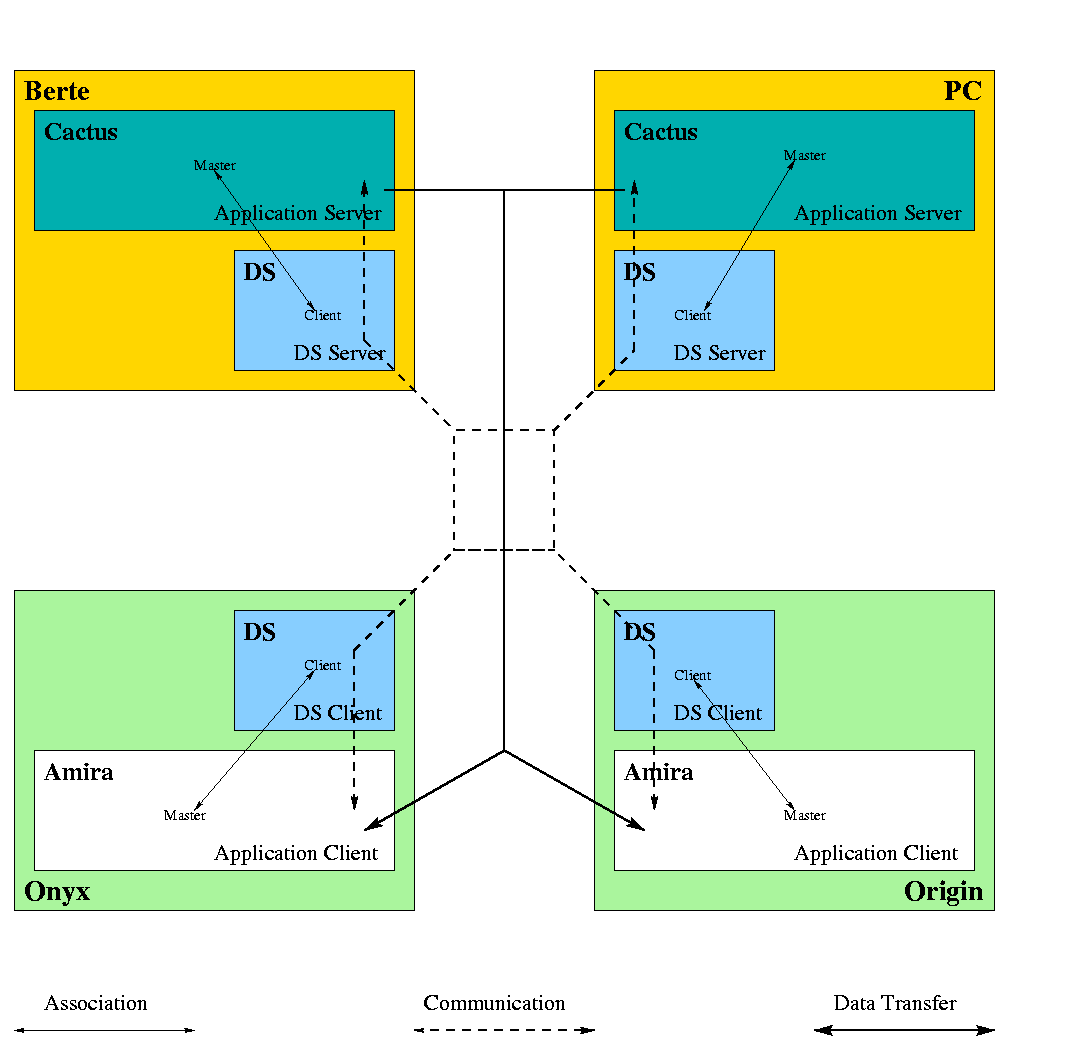
Mainly due to point C3 we decided to use a Data Server connecting Amira indirectly to the simulation.
Pro:
Contra:
Thus, the DS should run as a daemon!
According to our T3E Staff it's no problem to run daemons on T3E, even if it eats much computing time. But, anyway, it has to share the available computing time with other applications, since it's running on the int4eractive command nodes, where also compiling etc. takes part... An more severe limit meight be the available memory, 'cause this is also to be shared between all ionteractive applications.
Fortunately, during the next few month an OS upgrade is planned, which will provide an extra node (with 'big' memory) for memory intensive interactive applications/daemons. For us, so to say..;-) I will check with Garching that this is ok for them as well.
On an O2k an daemon will certainly rival in (memory and) CPU time with the application as well, espcially if there ar as many processes as nodes. But here is no way to prevent from this (or any ideas?).
For file I/O we plane to use HDF5 with an parallel, _distributed_ file layout, and MPI-IO, as well for _distributed_ collective IO. Here is the weakest point of the whole design, of course, we need your comments/suggestions/help right here! :
Parallel HDF5 relies on MPI-IO, which is available on the T3E since mid of March. We did not do much testing yet, but with MPI-IO available, parallel HDF5 should be coming soon on T3E as well(right??). (Remark: the parallel HDF5 tests coming with the HDF5 distribution are not compiling. They seem to be very old anyway... According to Albert Cheng, some tests on T3E are olready done.)
HDF5 usually writes a single file. We would like to have seperated files, for better performance (see Thomas Radkes I/O tests on turmoil, modi4 and origin!). HDF5 supports a so called mounting scheme for logical data groups, which has some paralells to unix fs mounting, but the term does not refer to really mounting external files into a HDF5 data set. Well, we would like to have exactly this, so is there a chance to get this???
Actually, Werner pointed out, that this should work already, at least there have been some comments about it in the mailing lists. Following Mike Folk at the NCSA it is not implemented yet. Can anyone clearify this, or even provide a piece of code as an example?
We want even more: if there would be a possibility to write a HDF5 data set into splitted files on one file system, why cant we do this distributed, on distributed file systems? One problem: MPI-IO (ROMIO) does not support writing on distributed FS (Right??). Steven Tuecke from Argonne mentioned once, that the ROMIO group might be interested in distributed I/O, too, so is there any chance that distributed IO will be supported in the near future?
The final file layout will look like this:

Every 'Data Chunk' is thought to be written to a single file. FS means file system: the files might be located on different file systems.
The advantages are clear: all processors can do local output, but since all data chunks + header form a single logical HDF5 file, the access of all data is transparent for every application, no recombination etc is necessary (actually, since the remote files are read by another process, and the local files are to be processed by the HDF5 lib, it's more a recombination 'on the fly').
It would be probably better to keep some information redundantly in each file. So, maybe, a special header file is not really necessary. Additionally, it might be easier to keep one single file per mashine, so MPI-IO can do some optimization for collective calls (following Rajeev Thakur).
Additionally, we can use multiple files systems, optimum size of IO blocks (by collecting data from a certain subset of procs, here 3), multiple files, and we minimize network transfer, and all of this should optimize IO speed!
The only drawbacks we see right now: there is a process necessary which reads the data located on a remote file system. We want to do this via an entry in inetd.conf on all servers, so if a a process reads a file, and the lib realises due to the header information that there are missing parts on a remote server, the daemon there is connected (and possibly automatically started), reads the parts of the file necessary, and puts them through a socket back to the application. The lib additionally could do some caching/staging as well...
The other possible problem is that, if we want to get a hyperslab or so, a read possibly goes over multiple files. Thus, if every file contains a self-contained HDF group structure, the hyperslab specification has to cover multiple groups! Or, alternatively, a group can extend over multiple (possibly all) data chunks. Is this possible?
Is there any chance to get the HDF5 group and the ROMIO group together to help to provide such functionality (in a time frame not exeeding the project time of 2 years...)???
Right now, mainly the request of data is described below. We are not yet sure how to send the data through the net. One of the nicest ways would be to get MPI-IO to write onto a socket instead of a file, but who is doing the sorting then? Another question is, which data format is to be used here. HDF5 is not streamable, FlexIO is, but we don't want someone rewriting/supporting the FlexIO library only for misusing it as an stream format! Another possibility is to use CORBA for this, but here we have to learn a lot, and test how it performs for large data sets. Additionally, we don't know if Corba (Mico) is available for all platforms. Other canditates are DCE and PVM. If this seems to be impossible for any reason, we possibly end up here with an own creation, using a protocol like the one described for the request part below.
So, if anyone has a better idea about this, let us know!
The IO API is thought to be very similar to HDF5. The reason for this is, that we can do the file IO very transparently by forwarding the calls to the native HDF5 library. In case of stream IO, the calls have to be mapped to our own stream lib (see section about stream IO), which has to implement a protokoll able to handle all possible data types.
In principle, it is wished to have the possibility of downsampling the data before writing them to disk or sending them over the net. If HDF5 provides this functionality (this seems to be the case according to Albert Cheng), we want to leave this task to the HDF5 lib (we possibly can't do it better ;), and implement only the things we need for streaming.
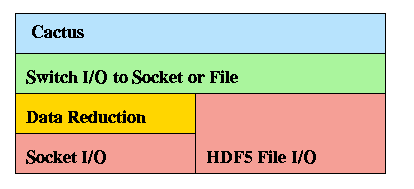
In case this is not possible in HDF5, we have to do our own reduction, which then will be a more general layer:

Anyway, the basic IO layer is thought to be a switch , which decides (by looking at the URLs/file handles) which lower layer has to be served.
'DS' stands for Data Server.



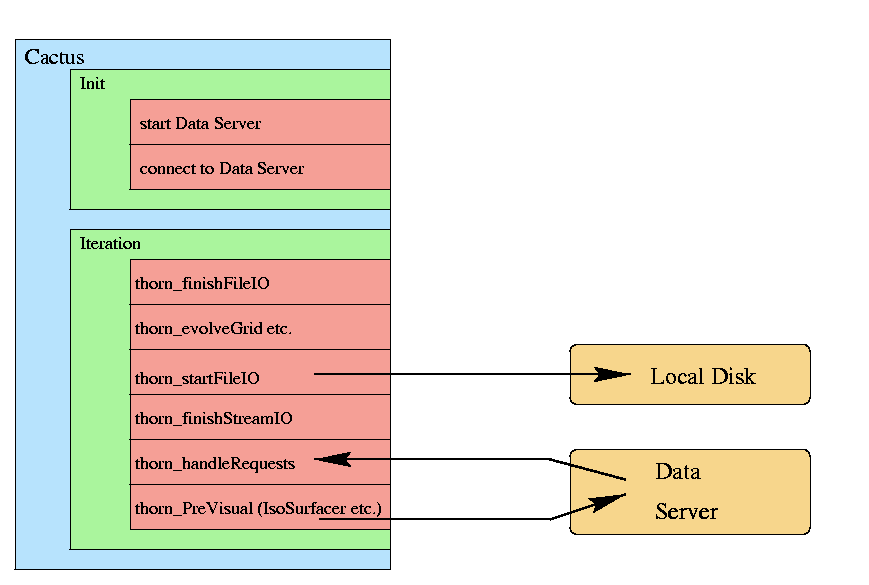
All requests are identified by a unique request ID, generated on visualization side. So, sent data can be associated to a certain request by this ID.
The list of former rcpts. is increase by every transmitter station (any mediate data server) to prevent from loops and multiple request handling. This is most important for broadcasting.
Syntax:
<REQUEST>
<HEADER>
<ID = 12345> # unique request ID
<VERSION = 0.1> # protocol version
<TAG = "donald"> # request tag
<TARGET = [<thorn_name> | DS | application | broadcast ]>
# request target
<TYPE = [init|info|control|data|previz|keepalive|answer]>
# request type
<SIZE = 5432> # size of request content
<RCPTS = [D727885EDB88EA62A779398BEE1099BA
5EE10EDB88EA62A77939A8BD7278899B
EDB88EA65EE1099BA2A779398BD72788]>
# list of former rcpts. of request
</HEADER>
<CONTENT>
<---something-depending-on-request-type--->
<---something-depending-on-request-type--->
<---something-depending-on-request-type--->
</CONTENT>
</REQUEST>
INIT:
Associates an application with the according data server
running on the same host. This request should be the first
one received by a data server, and should be sent by the
creator of the server. In this way, pairs of appls/ds
are formed, which will work together very closely.
For the situation that an application is distributed, and
for this (or for any other reasons) more than one data server
is to be associated to the application, these data servers
should be announced to each other as well. A new request type
for this is not necessary I think, the ASSOCIATED_ID could be
recogniced as know, or we set TYPE to "ASSOCIATED_DS" or so.
<PORT = 2500>
<ASSOCIATED_ID = "EDB88EA62A779398BD727885EE1099BA">
<PROGRAM NAME = "Cactus"
TYPE = "CCTK"
HOST = "berte.zib.de"
UID = 185
GID = 7
USER = radke>
.
.
.
Possibly other parameters a ds/application might
need for configuration.
INFO:
Request information, like available services, uptime, statistics etc.
<TYPE = IsRunning>
<TYPE = WhenStarted>
<TYPE = WhichTimeStep>
<TYPE = ListThorns>
<TYPE = ListFields>
<TYPE = ListControls>
<TYPE = ThornExists NAME = "<name>">
<TYPE = FieldExists NAME = "<name>">
<TYPE = ControlExists NAME = "<name>">
CONTROL:
Try to control the remote application. The process
invoking such requests should get information about
available controls, and can afterwards refer to
obtained control id's.
<SetValue NAME = "sample_size"
TYPE = "INTEGER"
VALUE = 128
>
<ToggleValue NAME = "light">
<SIGNAL = REGRID>
<SIGNAL = CHECKPOINT>
<SIGNAL = STOP>
<SIGNAL = SUSP>
<SIGNAL = CONT>
.
.
.
PREVIZ:
Request some computation on application side, and the
results. Here the same remark as for Control holds:
get information about available PreViz routines first.
<PREVIZ TYPE = "line"
START = "0.1, 1.4, -5.1"
>
<PREVIZ TYPE = "isosurface"
LEVEL = 0.001
>
.
.
.
Possible parameters depend on thorn to be invoked.
DATA:
Try to obtain actual data fields / sets from application.
Again, first get information about availability.
<DATA NAME = "fieldname"
RESOLUTION = 128
DOWNSAMPLING = 2
HYPERSLAB = "some HDF5 parameters"
XMIN = 2
XMAX = 4
YMIN = 3
YMAX = 5
ZMIN = 4
ZMAX = 6>
<PARAM NAME=hyperslab
VALUE=[hdf5-hyperslab-syntax]>
.
.
.
Possible parameters depend on field type and
visualization needs.
KEEPALIVE:
Now and then something should be sent just
to say: we are still out here.
<TIME = 924691596> # times since 01.01.1970 0:00
.
.
.
Possible other parameters I cannot think of right now... ;).
ANSWER:
This Request always refers to an ather, already handled
one, and gives information about its handling. This request
naturally should always flow in opposite direction to the
original request.
<ERRORCODE = [ NO_ERROR | ERROR_PERMISSION... ]>
.
.
.
This does not include any data to be sent, but only
information about request handling itself (aknlowledgement etc.).
Request Handling:
The thorn_handleRequests does nothing than :
The thorns themself have to parse the contents then, and do something according to its contents. the sending back of data, acknowledging etc. is completely done by the thorn itself, probably via an easy to handle API (well, _everybody_ should be able to write thorns...). If something goes wrong during parsing etc., the thorn now has to generate an approriate error message.